
Simple to Understand Output
Just want to jump straight in? Here is a link to the source code.
Harnessing the power of SentenceTransformers, this tool offers a sophisticated approach to understanding and clustering keywords by their contextual relationships.
This tool isn’t just about grouping similar keywords; it’s about uncovering the nuanced semantic connections that give depth to the relationships between words.
The result? A nuanced, contextually-rich keyword analysis that goes beyond surface-level data, providing a deeper insight into your content strategy.
The Specifics
The simply to use CLI app clusters your keywords and neatly appends the results to your source file in a new column.
Post clustering, it utilises the Pandas package to generate a user-friendly pivot table, presenting your data in an effortlessly understandable format. And for Windows users, there’s the added convenience of exporting this data into an interactive Microsoft Excel Pivot Table through the --excel-pivot option.
Moreover, the tool doesn’t stop at tabular data. It simultaneously creates an interactive tree map visualisation, conveniently saved as an .html file for your perusal. Prefer a sunburst chart? A simple switch --chart-type “sunburst” alters your visual output, tailoring it to your preference.
Choice of Interactive Charts
Simple, Yet Powerful CLI

Quick Start Guide
Install Python
- Download & Install Python: Go to the Python website (https://www.python.org/) and download the appropriate Python version for your operating system. Install Python and ensure to check the box that says “Add Python to PATH” during the installation.
- Set Up a Virtual Environment (Optional): It’s good practice to use a virtual environment for each Python project. This can help prevent conflicts between dependencies for different projects. To create a virtual environment, open a Command Line prompt, navigate to your project directory and use the command
python -m venv env. To activate the environment, usesource env/bin/activate(Unix or MacOS) or.\env\Scripts\activate(Windows). - Download the Source Code: Download the source code from Github. You can do this by cloning the repository if you have Git installed or by downloading it as a ZIP file and extracting it.
- Install Dependencies: The Python script will require certain dependencies listed in the
requirements.txtfile. (There are two different files, depending on whether you are using Windows, or another OS. Open a Command Line prompt, navigate to the directory containingrequirements.txt, and install these dependencies using the commandpip install -r requirements.txt. If you’re using a virtual environment, make sure it’s activated before running this command. - Navigate to the Script: Use the Command Line prompt to navigate to the directory containing the
cluster.pyfile downloaded from Github. You can do this with thecd [directory path]command. - Run the Script: Once in the right directory and with all dependencies installed, you can run the script using
python cluster.py "my keyword file.csv". Replace"my keyword file.csv"with the path to your .csv file if it’s not in the same directory ascluster.py.
Minimal Examples
Here are some minimal examples to get you started:
Autodetect volume column and run the script
python cluster.py "my keyword file.csv"
Specify your own volume column. (This could be impressions, or clicks from a GSC report).
python cluster.py "my keyword file.csv" --volume
Include an Excel Pivot Table in the final report (Windows users only), the script will use a Pandas Pivot table if it encounters an error.
python cluster.py "my keyword file.csv" --volume --excel-pivot
Settings and Options
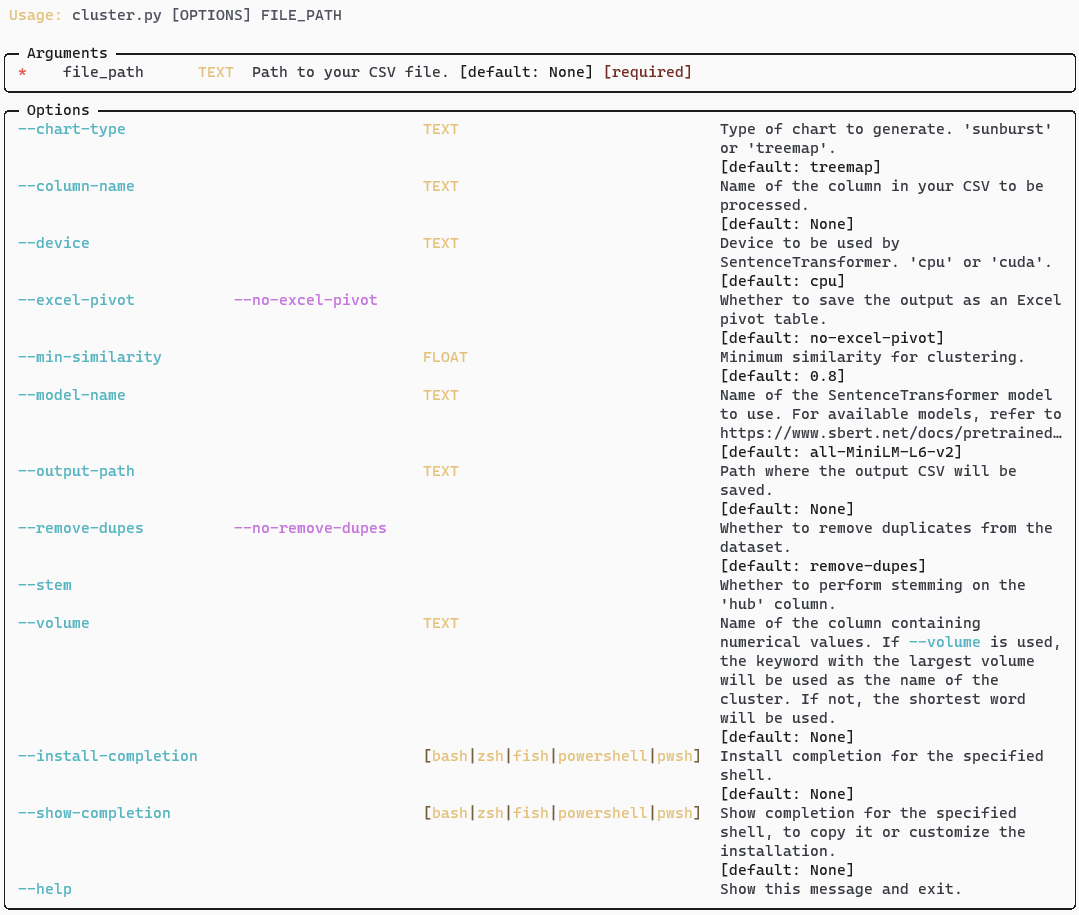
Settings
To View All Settings Within The App type cluster.py --help
Here’s a breakdown
--chart-type: Specifies the type of chart to generate. The default is a “treemap”, but a “sunburst” can also be created.--column-name: Specifies the name of the column in the user’s CSV file that will be processed.--device: Designates the device to be used by SentenceTransformer. The default is “cpu”, but “cuda” can also be used for GPU processing.--excel-pivot: When set to True, the output will be saved as an Excel pivot table. By default, this option is False.--file-path: Specifies the path to the user’s CSV file. This argument is mandatory.--min-similarity: Sets the minimum similarity for clustering. The default value is 0.80.--model-name: Specifies the name of the SentenceTransformer model to use. The default model is “all-MiniLM-L6-v2”. For a list of available models, users are referred to the SentenceTransformer documentation.--output-path: Designates the path where the output CSV file will be saved.--remove-dupes: When set to True, the program will remove duplicates from the dataset. By default, this option is True.--stem: When set to True, the program will perform stemming on the ‘hub’ column. By default, this option is False.--volume: Specifies the name of the column containing numerical values. If used, the keyword with the largest volume will be used as the name of the cluster. If not used, the shortest word will be used.
Which Sentence Transformer Should I Use?
By default the CLI script uses the pre-trained model called all-MiniLM-L6-v2 which provides a good balance between semantic scoring and speed. Most users will never need to specify a different transformer.
However, there are situations when it may make more sense to use something other than the default for either performance or language reasons.
For example, for languages other than English it is recommended to use the
paraphrase-multilingual-mpnet-base-v2
pre-trained model which has been trained on 50 languages.
If you have particularly large batch of keywords to process, then it is recommended to use a lighter transformer (Faster, lower semantic matching score).
Pre-trained models can be specified using the model-name switch. e.g.
--model-name multi-qa-mpnet-base-dot-v1
To view a list of recommended transformers please see: https://www.sbert.net/docs/pretrained_models.html
Use Case Example #1
Consolidation of Internal Links
A good use case for semantic keyword clustering is to cluster internal tag links to consolidate Page Rank.
The following site has user generated tags which link internally to images on the site.
This image taken from unsplash, has the following tags:
st patricks day images, St Paddys Day, Saint Patrick's Day,St. Patricks

Running them through the keyword clustering app conveniently groups them together to show the parent tag of Saint Patrick's Day.
This can help to inform internal linking strategy for large sites with a lot of tags to clean up.
Use Case Example #2
Create Negative Keyword Lists
Make light work of creating negative keyword lists by clustering the Search Terms report.
You can use the --volume switch to analyse clicks, impressions and cost data. Visualisations make it obvious where the spend is being depleted.
We don’t sell any of these products! Especially human arms!
Also worth noting with some modification it’s possible to get a median relevancy score by mixing in a crawl of your site’s pages. That way it’s possible see which keyword relevancy at a glance. (Are Google matching you to pages for products and services you don’t even stock and so on).
Use Case Example #3
Get a Visual Breakdown of the Type of Keywords Your Pages Are Ranking For
Get a treemap visualisation for frequency and type of keywords your site ranks for.
Just export your keywords from Search Console and run through the CLI app.
Use the --volume switch on the impressions or click column to get a visual representation of clicks / impressions per keyword cluster.
Current Limitations & Workarounds
Keyword Import
Keyword list must be in .csv format (UTF-8 or UTF-16)
Performance
Clustering keywords can be an intensive task which is only limited the resources of your machine. That said, clustering very large amounts of keywords will use a lot of system resources, namely RAM. There are some things you can do to mitigate against this:
- Reduce the size of your keyword import.
- Use a less resource-intensive Sentence Transformer, which typically offers faster performance with a lower semantic score.
- Set a VERY large page file. Setting the largest page file possible allows the system to use hard disk space instead of RAM. This is a great workaround to process very large jobs.
- Use the HDBScan version. This version is lighter that the default version and should allow for much larger jobs. Try this if you’re having issues
Conclusion
The Command Line Semantic Keyword Clustering Tool automates the complex process of semantic keyword clustering, transforming extensive keyword lists into insightful, manageable data.
With its intuitive interface, a variety of output options including interactive charts and detailed pivot tables, and the flexibility offered through a comprehensive set of settings, this is a powerful free tool for SEO specialists, content creators, and digital marketers.
Your feedback is invaluable in shaping the future of this tool. Feel free to fork the project on GitHub, submit pull requests, or share your unique use cases and experiences. Together, we can evolve this tool to make it the best it can be.
Get the Source Code on GitHub
- Download the PolyFuzz Version (Recommended)
- Download HDBSCan Version (Use this for very large batches or if you’re having issues with the PolyFuzz version)
Get in Touch
Let’s Work Together.
If you don’t want to mess around with Python, I offer a managed service on all my scripts. Get the insights without the fuss!
I’m also available for bespoke scripts and apps – ideal for internal team use.
I’m also happy to modify and tweak existing apps to suit individual requirements.
